A project that I’ve been meaning to work on for a while was a collection point for bulk IoT device data using AWS. Having had fun with various small, non-PC devices like Arduinos, it made sense to see if I could use these devices to send data of interest and build a collection point for dashboards and reports.
Typical applications might include transmitting weather data, energy consumption, levels, weights, proximity sensor status, and so on. I planned to use various AWS services, such as DynamoDB for the data storage, Lambda for the processing, and API Gateway to provide the internet endpoint for the devices to connect to.
The collection point was envisioned as a robust, high-performance, easy to use layer servicing the immediate needs of the devices as the design priority (things like device health monitoring and configuration) rather than providing detailed data analysis.
More detailed analysis would be done by processing the raw data into formats more amenable to analysis, such as relational DBMS.
The Ecowitt Weather Gateway
What I needed to find first was a simple, cheap device that could transmit data over the internet. The ability to transmit useful, interesting, and variable data was going to be much better than transmitting random data.
I found the Ecowitt GW1000 weather gateway product on Amazon, which provided a really simple device that could push temperature, humidity, and pressure data over a WiFi connection to a HTTP endpoint. The GW1000 serves as a WiFi hub for up to 8 different indoor sensor devices connected via WiFi, or one remote outdoor sensor connected through RF. I also purchased the WH32 outdoor sensor device, hoping to get more daily variations compared to the indoor sensor.
Configuring the GW1000 to send data
Similar to configuring many WiFi devices, configuring the GW1000 requires a phone app that connects to the temporary adhoc WiFi network created by the GW1000 when in setup mode. The app then connects to the GW1000 and it can then be configured to use a specific WiFi network. I can’t attest to whether it supports particularly robust WiFi security like WPA2/3, but it managed to connect to my guest network successfully.
The GW1000 data can be read and displayed inside the app if the phone happens to be on the same network.
The GW1000 can be configured to push data to a custom HTTP endpoint in addition to several preconfigured cloud weather reporting services so I configured my endpoint:
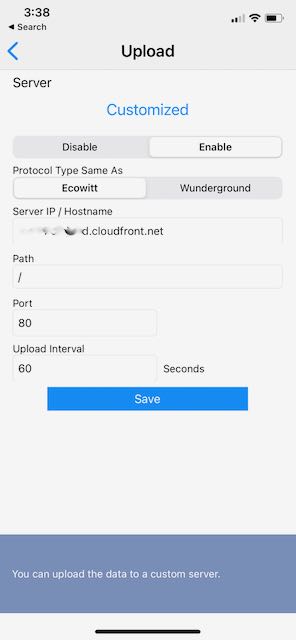
With the Ecowitt protocol selected, the custom endpoint receives the following HTTP POST data on a regular basis (the reporting interval is configurable from 16 seconds and up):
PASSKEY=EDB65C5xxxxxxxxxxxxxxx&stationtype=GW1000B_V1.6.3&dateutc=2021-02-17+22:58:13&tempinf=70.7&humidityin=35&baromrelin=30.345&baromabsin=30.345&tempf=58.1&humidity=42&wh26batt=0&freq=915M&model=GW1000_Pro
A couple of the variables do not seem relevant to my use, but the ones I used were the following:
| POST variable | Purpose |
| PASSKEY | Appears to be a unique identifier for the device |
| dateutc | Date of the weather report |
| tempinf | Built-in sensor (“in”=internal?) temperature in Fahrenheit |
| humidityin | Built-in sensor humidity |
| baromrelin | Built-in sensor pressure reading (mmHg) |
| tempf | External sensor (WH32) temperature |
| humidity | External sensor humidity |
I do store the original POST string in the database, so I don’t lose anything.
It’s not entirely clear whether the device can support SSL and I ran into problems trying to use an SSL URL endpoint. I did contact Ecowitt to ask and did not get a reply. Regardless, I implemented an HTTP passthrough to my SSL endpoint to get around this.
Creating a DynamoDB Table to store data
With the data sent by the GW1000 documented, the initial table structure to store the sensor data was created using AWS DynamoDB, a NoSQL DBMS. Given the purpose of this table was very much like an event log, a NoSQL approach seemed the simplest scalable approach. Besides, I wanted to stress-test the system later, so I was curious what sort of throughput I could get.
The initial DynamoDB table used the StationID (PASSKEY) as the Partition key and the Timestamp as the Sort key. These are the two mandatory keys or fields in each table row; the rest of the row’s attributes are completely user-defined. Each row can describe a completely different entity with different attributes, as long as it has a partition key and a sort key.
Logically, this table can store any number of weather reports generated by different weather stations, each identified by their StationID. A later iteration of this table still uses the StationID but replaces the SortKey with a composite AccessKey instead of the Timestamp. This is described below in the DynamoDB Refactor.
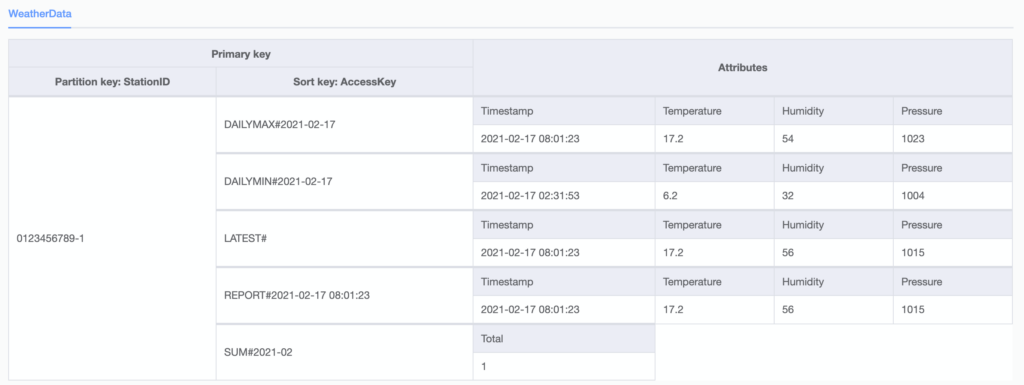
Adhering to the design goal of simplicity and high performance, this table can be used to check the status of a device by retrieving the latest data report using the a primary key comprised of the device ID and the string key “LATEST#”.
Creating a Lambda Function to receive data
With the DynamoDB table in place to hold the data, I wrote the receiving function to parse the POST request and insert the data into DynamoDB. I went with scalability and simplicity in mind and wrote a node.js Lambda function which will execute without needing a server instance to be running. The POST data is parsed and then written to DynamoDB in a single batch.
The function also implements the logic to update the most recent weather report, which is written as a separate row in the table, and other logic such as updating the minimum and maximum values for that station.
// Loads in the AWS SDK
const AWS = require('aws-sdk');
const querystring = require('querystring');
const ddb = new AWS.DynamoDB.DocumentClient({region: 'us-west-2'});
exports.handler = async (event, context, callback) => {
// Captures the requestId from the context message
const requestId = context.awsRequestId;
console.info("EVENT\n" + event.body)
// Handle promise fulfilled/rejected states
await createMessage(requestId, event).then(() => {
// If success return 201
callback(null, {
statusCode: 201,
body: 'OK',
headers: {
'Access-Control-Allow-Origin' : '*'
}
});
}).catch((err) => {
// If an error occurs write to the console
console.error(err)
})
};
// Function createMessage
// Writes message to DynamoDb table Message
// Returns promise
function createMessage(requestId, event) {
const postParams = querystring.parse(event.body);
const sensorId = postParams.PASSKEY;
const day = Date.parse(postParams.dateutc);
const dayOnly = postParams.dateutc.substring(0, 10);
const tempinf = parseFloat(postParams.tempinf);
const humidityin = parseFloat(postParams.humidityin);
const baromrelin = parseFloat(postParams.baromrelin);
const tempf = parseFloat(postParams.tempf);
const humidity = parseFloat(postParams.humidity);
const baromrel = parseFloat(postParams.baromrel);
var batchParams = {
RequestItems: {
"WeatherData" : [
{
PutRequest: {
Item: {
'StationID' : sensorId,
'AccessKey' : "REPORT#" + postParams.dateutc,
'Timestamp' : postParams.dateutc,
'Temperature' : tempinf,
'Humidity' : humidityin,
'Pressure' : baromrelin,
'RawData' : event.body,
}
}
},
{
PutRequest: {
Item: {
'StationID' : sensorId,
'AccessKey' : "LATEST#",
'Timestamp' : postParams.dateutc,
'Temperature' : tempinf,
'Humidity' : humidityin,
'Pressure' : baromrelin,
'RawData' : event.body,
}
}
},
{
PutRequest: {
Item: {
'StationID' : sensorId + "-1",
'AccessKey' : "REPORT#" + postParams.dateutc,
'Temperature' : tempf,
'Humidity' : humidity,
'Pressure' : baromrelin,
'RawData' : event.body,
}
}
},
{
PutRequest: {
Item: {
'StationID' : sensorId + "-1",
'AccessKey' : "LATEST#",
'Temperature' : tempf,
'Humidity' : humidity,
'Pressure' : baromrelin,
'RawData' : event.body,
}
}
},
]
}
}
return ddb.batchWrite(batchParams, function(err, data) {
if (err) {
console.log("Error");
} else {
console.log("Success", data);
}
}).promise();
}API Gateway
The Lambda function needs to be driven by an HTTP POST receiver. Creating an AWS API Gateway REST API with a POST method satisfied this requirement. As the REST integration expects to use JSON data by default, the Use Lambda Proxy Integration option for the Integration Request needs to be checked in order for the POST variables to be accessible from the Lambda function.
HTTP to HTTPS API Workaround
The API Gateway endpoint configured in the above step ended up being bound to an SSL URL, and I was not able to find any way around this in the API Gateway, nor was I able to verify if the GW1000 could POST to an SSL URL.
The workaround within the AWS ecosystem was to create a CloudFront Distribution to expose the API as HTTP. The CloudFront distribution needs to be set to not cache any requests and to send the requests directly to the originating site (the SSL site). CloudFront also helps to shorten the API URL, obfuscates the AWS region in the URL, and (I assume) provides other performance benefits.
Refinements: Locust Test Harness
I had previously built a Locust test server instance on my AWS account, and it was fairly easy to start up the instance and create a test harness for submitting weather reports to the API. This gives me a great way to assess API performance under load.
Refinements: DynamoDB Refactor
With the initial proof of concept system finally working properly, I set out to refactor the DynamoDB table to more accurately represent the anticipated usage patterns. This is one key aspect where NoSQL databases differ from RDBMSes: NoSQL database schemas are optimized for the type of usage they expect, while RDBMS schemas tend to start from an idealized and normalized view of entities and relationships.
An RDBMS design for this database would typically contain several tables representing different entities, and connected via SQL JOIN statements. In some extremely normalized designs, it could have tables to represent discrete values – a Humidity reading table, a Pressure reading table, etc.
The NoSQL database design here is quite different. Different constraints help drive the design, and the transactional, write-once, but read many times nature of the table is key. As well, since NoSQL is schemaless, a single table can be used to represent related data or metadata, such as totals and summaries, that could require separate tables in SQL.
There are several operations I identified as a user of the system. By understanding these, the partition key and sort key for the table were designed accordingly. These are the operations it was designed for:
- Submit a weather report from all connected devices
- Display the current weather report for a device, including minimum and maximum values for that day
- Display values in graph format for a given time period
The DynamoDB schema was then designed for the following:
- Add a new Weather report row
- Update the “latest” Weather report row so the latest values for that station can be retrieved
- Update statistical information such as maximum and minimum values for each day / month period
- Find all reports for a station for a date period
The Partition key was chosen as the StationID identifier. My assumption and hope is that the StationIDs are fairly randomly distributed, and will help to distribute workload across DynamoDB.
The Sort key was changed to become a composite key called “AccessKey” with specific formatting rules. This access key is constructed by the Lambda function, and when queries are made against the database, specific rows can be retrieved quickly by manipulating the AccessKey. These rows include:
- Standard weather report row (“REPORT#yyyy-mm-dd hh:mm:ss”)
- Latest weather report for this station (“LATEST#”)
- Min / Max report for this station for a day period (“MIN#yyyy-mm-dd”)
- Totals report for this station for period (“TOTAL#yyyy-mm-dd”)
By manipulating the AccessKey variable, one or more rows satisfying the query can be returned. For example, asking for SortKey in between “REPORT#2021-02-17” and “REPORT#2021-02-19” will return all weather report rows for the 17th and 18th of February 2021. This technique involving the use of magic values like “REPORT#” inside keys would rarely be used in a traditional RDBMS; rather, datetime columns would be indexed and included as part of the SQL WHERE clause. However, this technique is part of the reason why NoSQL table data access can be extremely fast.
Now, these special rows representing the latest, min and max reports need to be constructed in the Lambda function as each new data report is processed. The process is straightforward:
- Write the standard weather report
- Write the standard weather report as above, but set the AccessKey to “LATEST#”. In effect, this is a duplicate row, but gets read quickly with its own specific AccessKey instead of having to read rows sorted by date and time.
- Min and Max can be created as running updates; again, the current row data can be compared to the Min and Max rows, and the Min and Max rows updated if necessary
- Totals can also be updated as a running increment of the existing totals
DynamoDB Triggers
DynamoDB Triggers are in place on the Weather Data table. These triggers are an alternative way to implement business logic such as updating the latest weather report row, Min/Max values, and so forth, rather than writing these into the Weather Report submission URL.
I plan to test these further to assess the overall impact and pros and cons of this approach.