The challenge: process 100 years of newspaper articles related to Scottish associations in Vancouver to try to make sense of what each means.
My wife is currently working on her Master’s dissertation in family and local history and exploring the Scottish association culture in Vancouver. Much of the association history in the city spans from the 1880’s through the 1980’s, from the city’s founding in 1886, the rise of associations serving the needs of the Scottish diaspora, and the decline of these associations in the 60’s and beyond.
Although her research also includes association archive files and taped interviews, Newspapers.com’s searchable archive of newspapers proved to be a useful source for association activities. Searching by each association name retrieves articles related to its activities: meetings, concerts, dances, Burns Night suppers, fundraisers, and general business. Newspaper mentions are a good proxy for association health, due to the lack of other communication channels during the time period analyzed – newspapers were arguably the medium of choice to help bring in new members and to publicize events held by these associations.
The idea of manually going through the estimated 29,000 articles in this time period was much too arduous, so my wife had initially planned to just perform a broader summary of articles by date or source, and not dive into the details of each article. Just a simple count of articles by year shows the upward growth into the WWI / WWII period, then steady decline into the 80’s. The question was if there was more to be gained in understanding the data further?

I had previously done some historical statistical analysis of census documents decades ago when working on my degree in university. In that, I used SPSS and manual data entry of 1890’s census data to look at typical occupations for Chinese in British Columbia.
I pitched the idea to her for a modernized approach using computing power to read through the results generated by newspapers.com to help categorize each search result. All using a wonderful mashup of technology, from Azure, local MySQL, .NET, C#, Excel, Jupyter, and Python.
This is what I did:
Step 1: Collect newspaper images into CSV
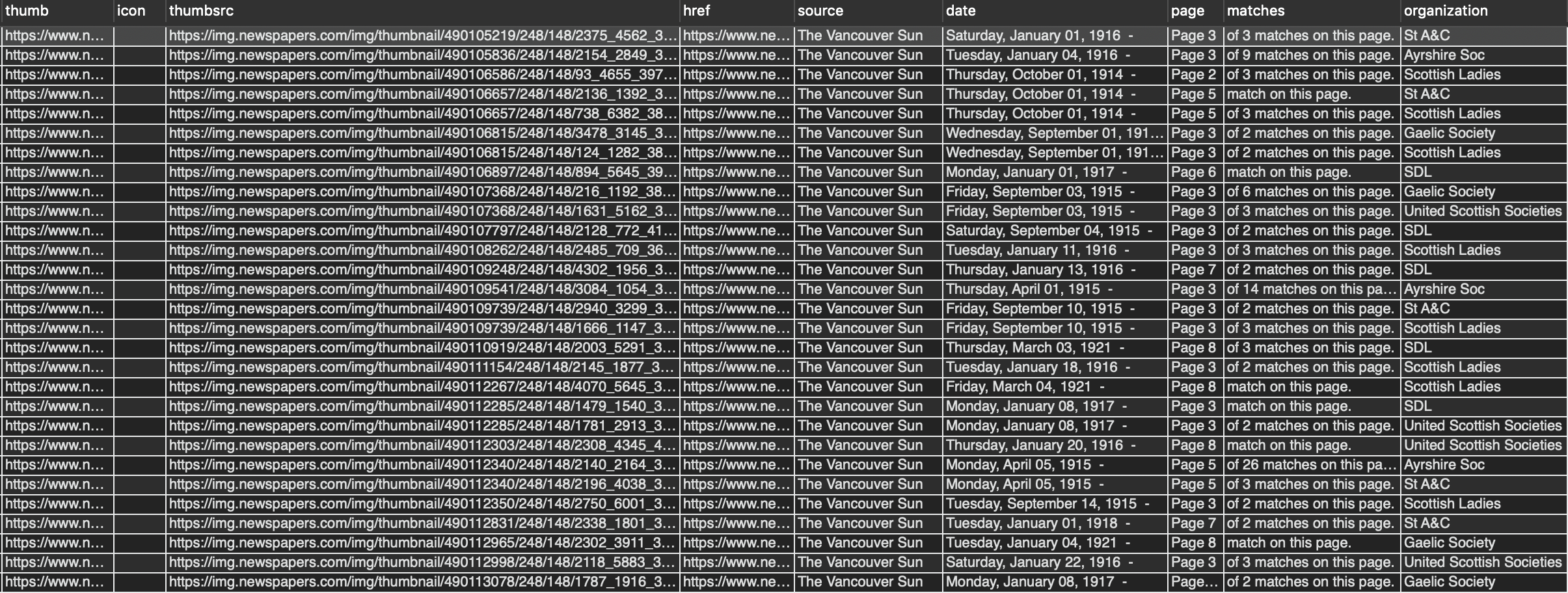
The initial step was conducted through Newspapers.com and a Chrome browser-based web scraping tool. A query was executed through newspapers.com’s search interface for each organization of interest, and the search results were scraped into a CSV file. The CSV contained the query, association name, newspaper name, and date, and URL of the article thumbnail graphic.
Inquiries were made to Newspapers.com to see if queries could be executed directly without needing to scrape pages, but their support staff were not able to provide us with anything. It would have been beneficial (and perhaps a good service offering – hint) for Newspapers.com to have features for researchers such as a REST API for obtaining results or fuller views of the newspaper pages, as this would have saved us tremendous amounts of time and gained greater accuracy. It would certainly be a feature we would have gladly paid for above and beyond our existing paid subscription.
The dozens of resulting CSV files were assembled together into one large CSV file.
Step 2: Get around Excel date limitations
A well-known and annoying problem with Excel for historians is its inability to work with dates before 1900. Cells cannot be formatted as a date type as a result and any date math does not work. Knowing that Excel would be the analysis tool used, the workaround was to write an Excel macro to parse the date returned from newspapers.com (e.g. “Thursday, October 01, 1914 -“) into discrete year, month, day, and day of week columns within the spreadsheet.
Step 3. Load MySQL database
The Excel file was imported into a local MySQL database on my Mac resulting in 29,237 rows.
Step 4: Azure text recognition
Next was investigating text recognition on the thumbnail graphic. Microsoft offered the ability to perform text recognition through Azure Cognitive Services Computer Vision. A quick search through Microsoft’s samples found me what I was looking for: .NET samples for uploading an image for processing, calling the API, and receiving back a result containing the text. All that was needed was to wrap that with database access code. As I still had some remaining credit on my Azure account, Azure got the nod for this part.
Using Visual Studio, I wrote a quick and dirty C# console program that would loop through the records in the MySQL database using Entity Framework, download the image thumbnail JPEG file from newspapers.com to the machine, submit the image to Azure Cognitive Services’s text recognition API, and save the recognition results back to the MySQL database.
As the sequence of operations was run in a single thread, the total recognition phase took around 7-10 seconds per row, or a total of three days to complete for the 29,000+ rows. Running multiple worker threads would have sped up the process, but I was concerned about running up costs if there were any bugs in my implementation leading to reprocessing rows by mistake, so I erred on the side of watching the system closely.
The initial testing of the application was thankfully possible at the free service level (limit of 5,000 calls / month), and running of large batches for the remainder was done at the paid service level.
The total cost for the Azure services consumed was about $69 Canadian and yielded results like the following:
H. N. Tait, president, wil chairman, and N. K. Wright he master of ceremonies of annual Glasgow and Dis Association's Burns' banquet dance on Friday at 6:45 p.m Hotel Georgia.
Analysis of data using MySQL queries yielded good insight finally into the contents of the articles, which were finally visible, and some useful grouping and filtering could be done. Certainly, categorization using SQL queries such as
select count(*) from articles where content like '%dance%'
would yield useful results, but the limitations of the simple string matching were more apparent when the actual contents were reviewed.
Step 5: Data analysis with Pandas and Jupyter
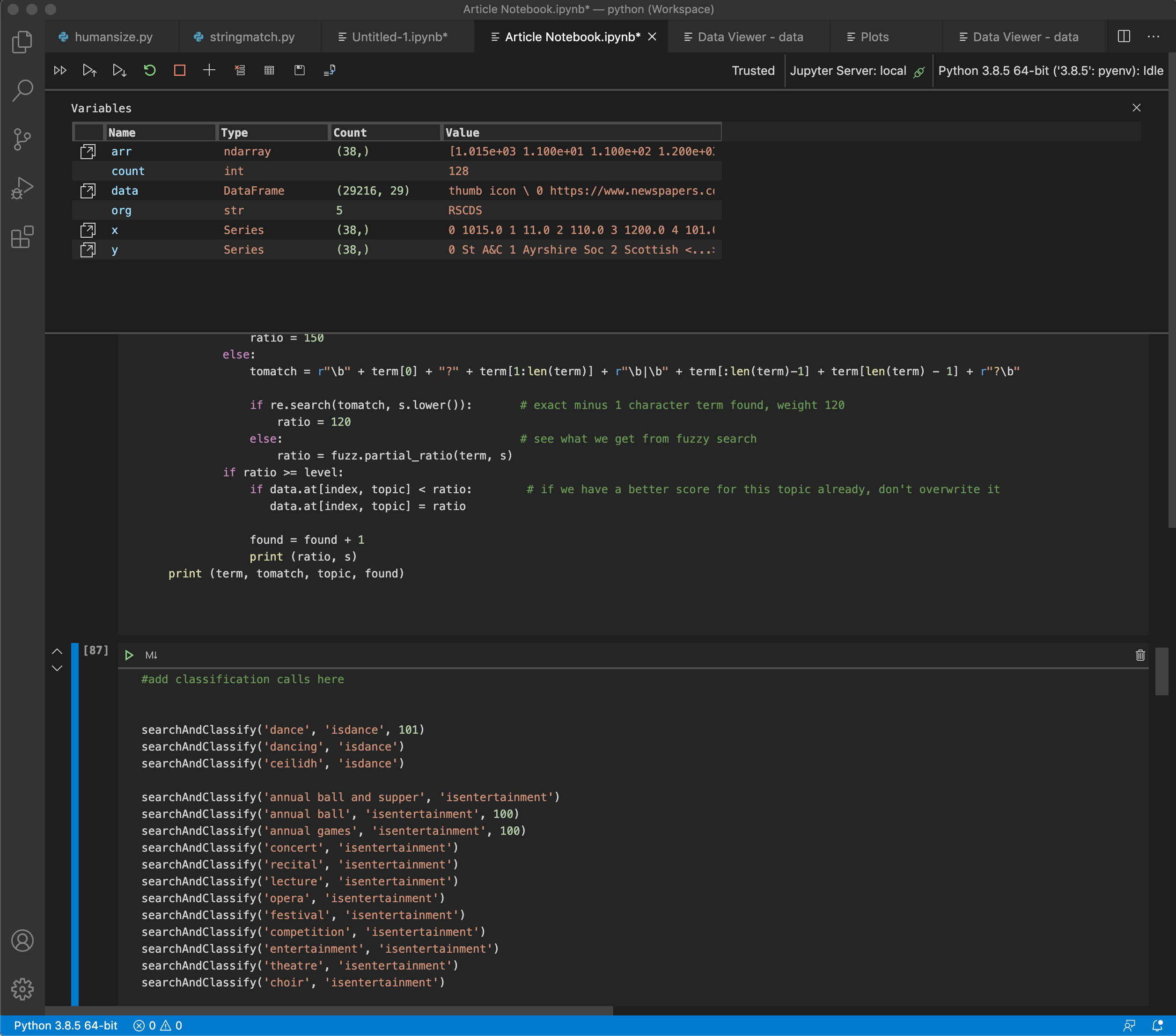
In order to make the analysis and categorization step easier, I wanted to work with Python’s data science friendly tools, including NumPy and Pandas. The data in the MySQL database was exported into Excel format and imported into a Pandas DataFrame inside the Jupyter notebook for more interactive analysis.
Jupyter conveniently allows the writing of Python analysis code and viewing of results in a single document, rather than jumping between a code environment and viewing environment. The idea was to essentially work with the data in 2-D columns and rows, and augment it with analysis results in additional columns.
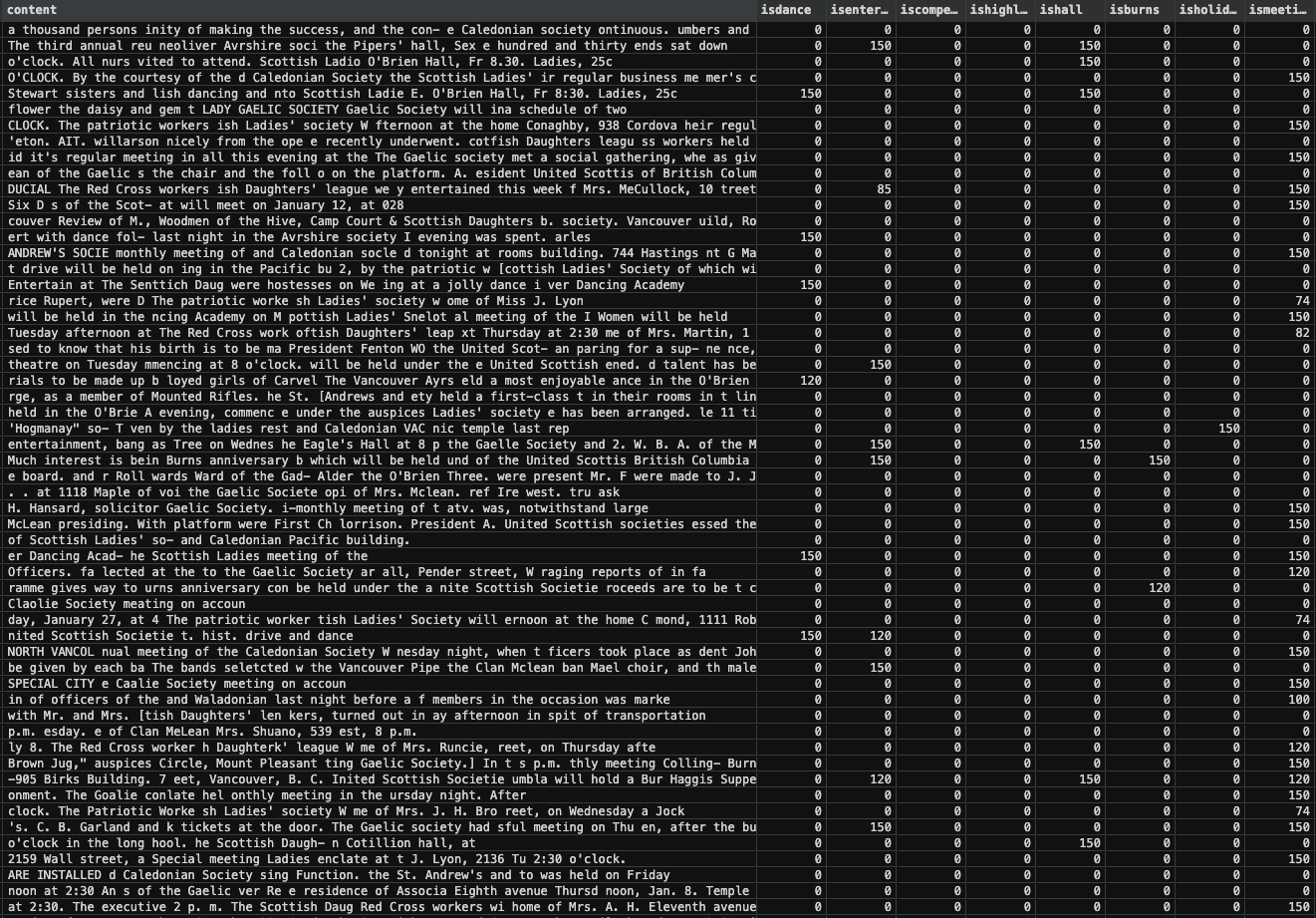
The processed dataframe is then exported in Excel spreadsheet format. This new spreadsheet appears identical to the input spreadsheet, with the addition of new columns signifying the probability that row contains text terms related to that column’s category (“dance”, “fundraising”, etc.).
Step 6: Categorize text based on string matching
The next step is to tag each article into different categories such as “fundraising”, “entertainment”, or “meeting” based upon the text content and analysis required.
One challenge was the nature of the returned text was not perfect; in many cases the newspapers.com thumbnail only contained a fragment of the article, truncating many words, or incorporating words from other articles in the paper.
In most cases, the recognition performed well when the thumbnail contained good data:
H. N. Tait, president, wil chairman, and N. K. Wright he master of ceremonies of annual Glasgow and Dis Association's Burns' banquet dance on Friday at 6:45 p.m Hotel Georgia.
In other cases where the thumbnail contained multiple columns, Azure joined unrelated columns, truncated words, and identified words incorrectly:

est she can- lumbia "sorters the me rs of the Gaolid up pape angements for conditio to be held in Press he evening of been oh
The first guess was to determine the category of the article based on key terms. Scanning all 29,000 rows of text showed words like “donate” or “dance” showed up frequently and matched the intended statistical analysis of popular association activities like fundraising and dancing. An example of rows of text containing the word “donate” are the following:
centre donated by ter raffled in aid of du the gaelic society abl et no. 262. the su to $42.90. wo fes the iss maude avery. at the last business lottish ladies societ 25 was donated to rder of nurses. arra made for a picnic to r the sunshine fund o d caledonian society & articles donated by the ld in the moose hall or ock. the auction will vement in the death mother. gaelic society ank those who foun d at funeral service donated flowers or
In this case, the word “donated” is quite clear in the text. Other words found in the overall text results related to fundraising were “rummage sale”, “bursary”, “scholarship”, and these were also added into the dictionary to tag any occurrences under fundraising.
Note that in the last example, “donated” refers to the flowers and the article intent is not fundraising, so there will be inevitable miscategorizations when purely tagging based on the presence of text in the article rather than doing a deeper lexical analysis.
A single article can be tagged under multiple categories depending on the search terms, like the following winner, which hit on the dancing, fundraising, entertainment, memorial, hall, and competition categories:
trinity holds rummage sale at 8:30 a.m. in the Memorial Hall, 514 Car- narvon, New Westminster. Highland Society concert at 8 p.m. in Scottish Audito rium, Twelfth and Fir, fea tures Scottish and Gaelic sing ing piping and dancing.
Step 7: Refining the fuzzy text matching algorithm
To obtain broader categorization beyond exact string matches, a fuzzy string matching function was implemented to cover three possibilities when searching for a term inside the recognized text:
- Complete search term found – highest match score (150) using regex
- Truncated search term (missing one character at the beginning or end of string and preceded by either a space or by the beginning of the line) – next highest match score (120) using regex
- Search term found in fuzzy search. The Levenshtein string distance algorithm (implemented in the Python fuzzywuzzy module), capable of matching phrases – match score 100 and below
The match score for the string was then compared to a manually-derived threshold ratio, above which a match was declared. A default match score of 85 was found to be suitable for most search terms. This match score was then saved to the dataframe column for that category to allow room for further analysis as opposed to saving a binary True/False value.
A tighter match threshold was needed for smaller words whose truncated or fuzzy search versions could trigger false matches. The search term “band” (i.e. pipe band) is an example where a tighter match threshold of 150 is needed, as its fuzzy derivative “and” matched many unrelated articles.
The resulting function is called searchandClassify(term, category, level), taking in parameters for the search term, the category to score for a match, and the threshold level for match (defaulting to 85 if not specified).
Each search term is checked by calling the searchandClassify() function. Currently, each term is manually hardcoded to obtain the best results while eliminating false positives by fine-tuning the level parameter.
Examples of the analysis code that calls searchandClassify() are as follows:
...
searchAndClassify('concert', 'isentertainment')
searchAndClassify('donated', 'isfundraising')
searchAndClassify('amount', 'isfundraising', 150) # needs exact match to skip "mount" in "mount pleasant"
searchAndClassify('red cross workers', 'ismeeting', 80) # SDL
...
Fuzzy text searching using the Levenshtein distance can be useful in categorization situations where a phrase is applicable. This can help sidestep limitations of single word phrases being too broad to categorize. In the above example, “red cross workers” as a term can help select for that phrase and limited variants, where “workers” may be too broad.
Step 8: And finally, back to Excel
As Excel was a much friendlier end-user tool, the Pandas dataframe was exported into a final Excel spreadsheet for further analysis and creation of visualizations.
Future Steps: Machine Learning
An interesting avenue for improvement of results came up through the analysis of the text data. Categorizing articles purely on the presence of words can be quite successful in this context, but outliers like “donate” present an interpretation problem. As well, the unfortunate combination of text across unrelated columns (as a result of the OCR process) has the effect of arbitrarily splitting up key phrases that can be used to categorize articles.
There are some cross-cutting terms that cannot be successfully categorized, or appear in articles with different intent. These words are “hall”, the aforementioned “donate”, “drive”, and some others.
A possible way of solving this is to break out individual terms of interest without categorization, then apply a probabilistic matching based upon the presence of a list of words.
This of course is the realm of machine learning, and such an algorithm would only require straight text matching (level 1 and 2) to assemble the list of terms found in the article prior to analysis.
Depending on available time and resources, this may be an avenue worth pursuing, though the benefits in this particular dataset may not be worthwhile because most terms found uniquely map 1:1 to their categories. As well, with all ML approaches, a training dataset would need to be assembled, the effort to do so may not be worthwhile in this case.